
【第六届信也科技杯图像算法大赛】智能零售柜商品识别_数据集-飞桨AI Studio星河社区 (baidu.com)
这里下载了该数据集用作实验,下载完成后解压,得到如图文件夹内容
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["hat", "person"]
#classes=["ball"]
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if(prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()该脚本使用要求一:
创建如图所示的文件夹列表,将下载压缩包中对应的Annotations文件夹和JPEGImages文件夹内容移入其中相应位置,并用pycharm打开顶层文件夹VOCdevkit
将该脚本文件放在和VOCdevkit文件夹同级目录下,(名字不重要)

将python脚本中的chass类更改为xml中已经标注好的类
而在我们下载的这个数据包中,存放类的文件是lables.txt(我猜的)
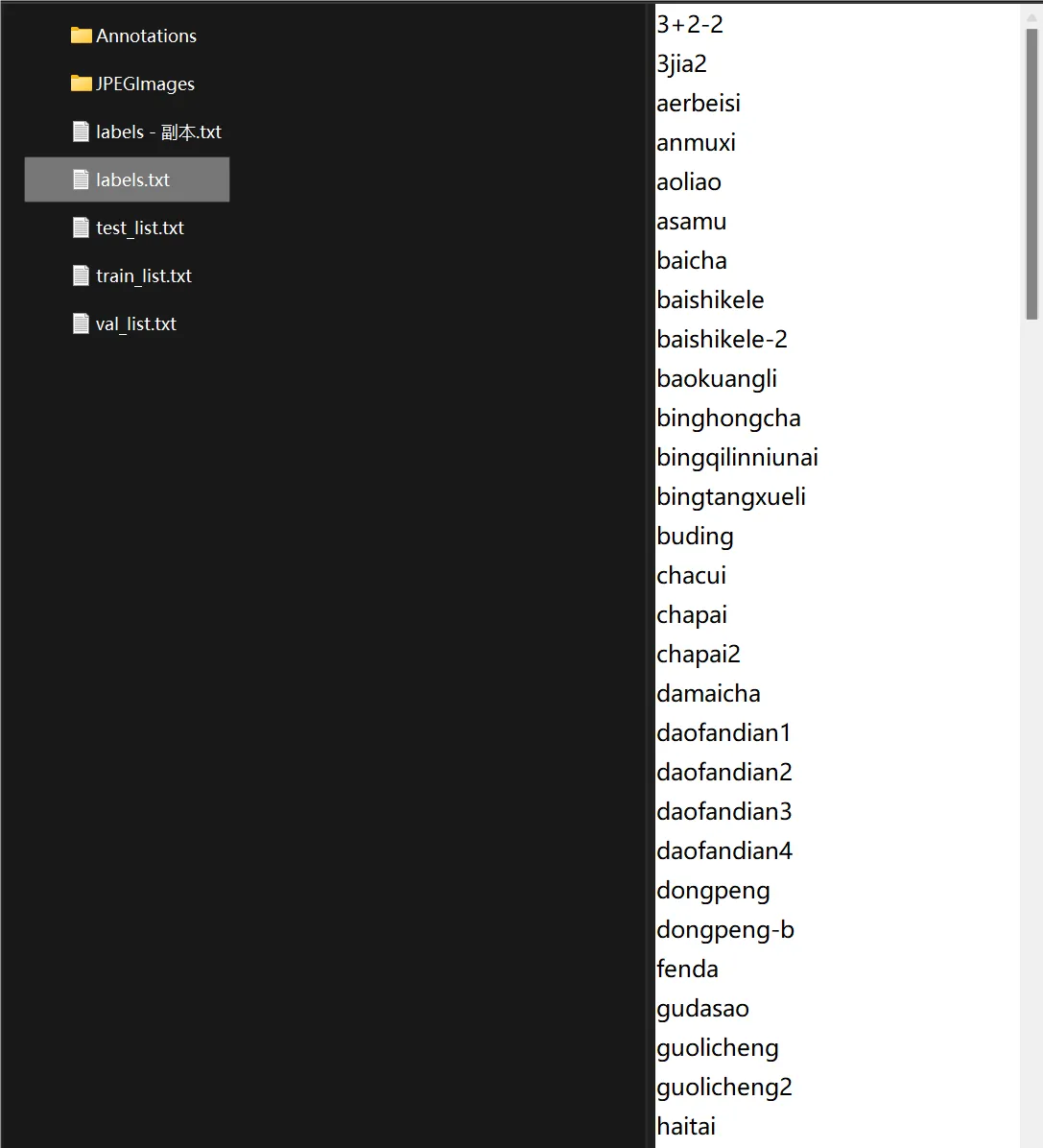

classes = ["3+2-2", "3jia2", "aerbeisi", "anmuxi", "aoliao", "asamu","baicha","baishikele","baishikele-2","baokuangli","binghongcha","bingqilinniunai","bingtangxueli","buding","chacui","chapai","chapai2","damaicha","daofandian1","daofandian2","daofandian3","daofandian4","dongpeng","dongpeng-b","fenda","gudasao","guolicheng","guolicheng2", "haitai", "haochidian", "haoliyou", "heweidao", "heweidao2", "heweidao3", "hongniu", "hongniu2", "hongshaoniurou", "jianjiao", "jianlibao", "jindian", "kafei", "kaomo_gali", "kaomo_jiaoyan", "kaomo_shaokao", "kaomo_xiangcon", "kebike", "kele", "kele-b", "kele-b-2", "laotansuancai", "liaomian", "libaojian", "lingdukele", "lingdukele-b", "liziyuan", "lujiaoxiang", "lujikafei", "luxiangniurou", "maidong", "mangguoxiaolao", "meiniye", "mengniu", "mengniuzaocan", "moliqingcha", "nfc", "niudufen", "niunai", "nongfushanquan", "qingdaowangzi-1", "qingdaowangzi-2", "qinningshui", "quchenshixiangcao", "rancha-1", "rancha-2", "rousongbing", "rusuanjunqishui", "suanlafen", "suanlaniurou", "taipingshuda", "tangdaren", "tangdaren2", "tangdaren3","ufo", "ufo2", "wanglaoji", "wanglaoji-c", "wangzainiunai", "weic", "weitanai", "weitanai2", "weitanaiditang", "weitaningmeng", "weitaningmeng-bottle", "weiweidounai", "wuhounaicha","wulongcha","xianglaniurou","xianguolao","xianxiayuban", "xuebi", "xuebi-b", "xuebi2", "yezhi", "yibao", "yida", "yingyangkuaixian", "yitengyuan", "youlemei", "yousuanru", "youyanggudong", "yuanqishui", "zaocanmofang", "zihaiguo",]脚本使用:
脚本使用注意点:
特别要注意的是,classes里面必须正确填写xml里面已经标注好的类,要不然生成的txt的文件是不对的。TRAIN_RATIO是训练集和验证集的比例,当等于80的时候,说明划分80%给训练集,20%给验证集。
这里,我们把解压后压缩包中的lables.txt文件复制一份,重命名为classes.txt
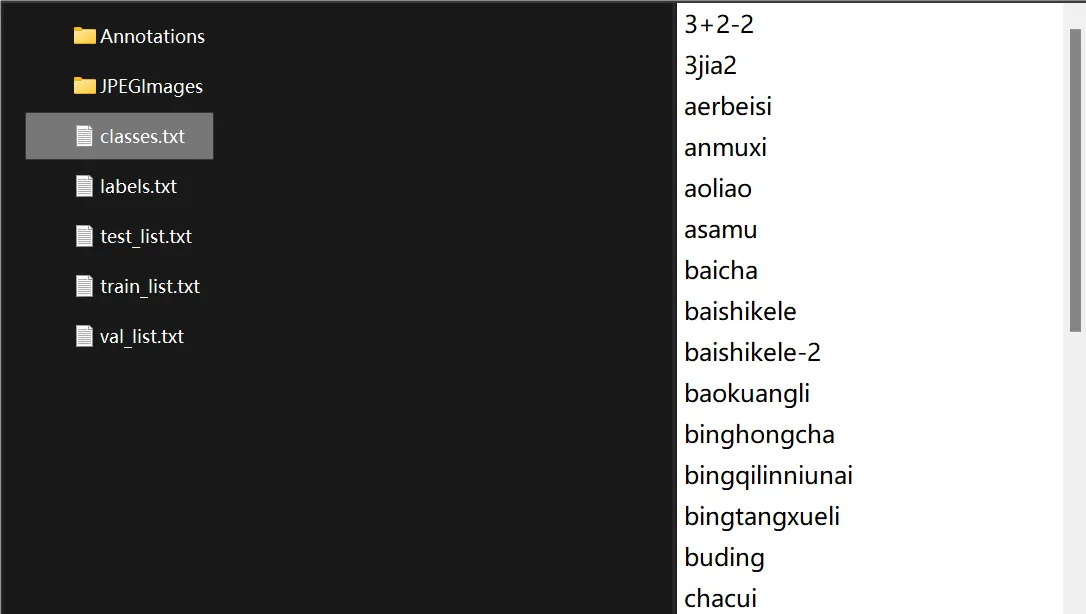
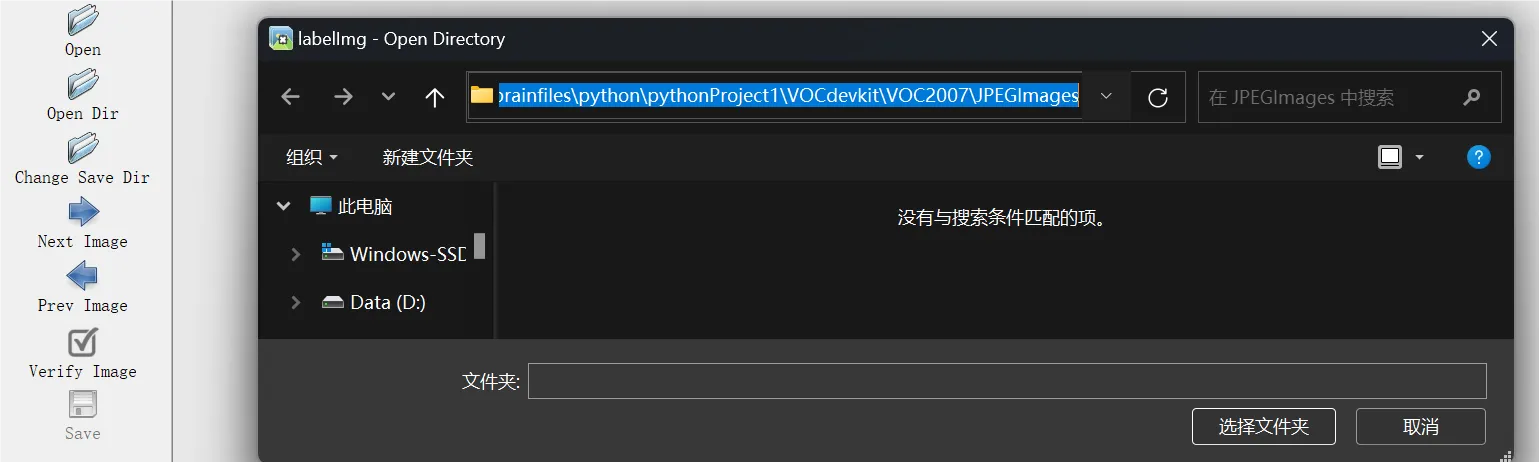
把它拖到YOLOLables文件夹中,打开labelImg.py标签编辑程序,将Open Dir和Change Save Dir对应目录JPGEImages和YOLOlables选中
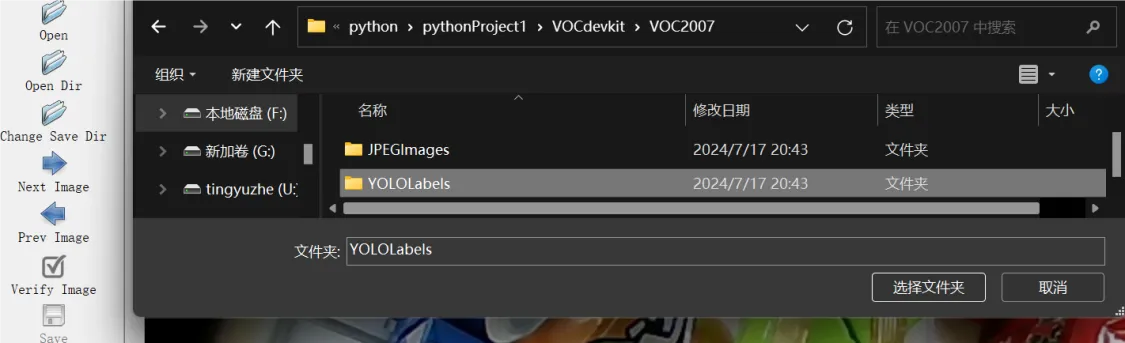
若labelImg在选中过程中闪退,在c盘/user/用户目录下删掉这个文件
完成上述步骤后,在右下角随意选一张图片,然后……

