
https://github.com/ultralytics/yolov5/tree/v5.0
下载解压后yolov5-5.0文件夹中相关文件的作用
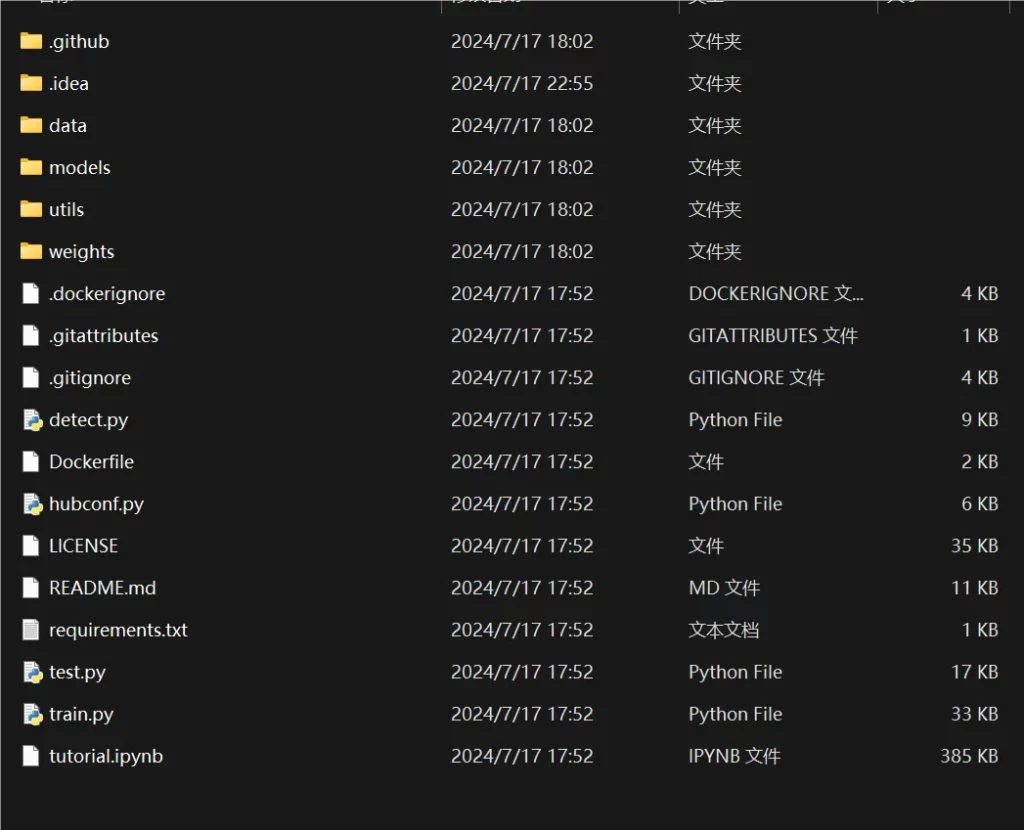
- data:主要是存放一些超参数的配置文件(这些文件(yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称);还有一些官方提供测试的图片。如果是训练自己的数据集的话,那么就需要修改其中的yaml文件。但是自己的数据集不建议放在这个路径下面,而是建议把数据集放到yolov5项目的同级目录下面。
- models:里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别为是s、m、l、x。从名字就可以看出,这几个版本的大小。他们的检测测度分别都是从快到慢,但是精确度分别是从低到高。这就是所谓的鱼和熊掌不可兼得。如果训练自己的数据集的话,就需要修改这里面相对应的yaml文件来训练自己模型。
- utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
- weights:放置训练好的权重参数。
- detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
- train.py:训练自己的数据集的函数。
- test.py:测试训练的结果的函数。
- requirements.txt:这是一个文本文件,里面写着使用yolov5项目的环境依赖包的一些版本,可以利用该文本导入相应版本的包。
在pycharm打开解压后的文件夹yolov5-5.0,打开requirements.txt这个文件,可以看到里面有很多的依赖库和其对应的版本要求。我们打开pycharm的命令终端,在中输入如下的命令,安装依赖项。pip install -r requirements.txt
一般为了缩短网络的训练时间,并达到更好的精度,我们一般加载预训练权重进行网络的训练。而yolov5的5.0版本给我们提供了几个预训练权重,我们可以对应我们不同的需求选择不同的版本的预训练权重。
https://github.com/ultralytics/yolov5/releases
预训练权重越大,训练出来的精度就会相对来说越高,但是其检测的速度就会越慢。
这里下载的是s文件,下载后放到weights文件夹重命名为yolov5s.pt
修改参数
- data下的voc.yaml文件,将该文件复制一份,将复制的文件重命名,最好和项目相关,这样方便后面操作。这里是check.yaml
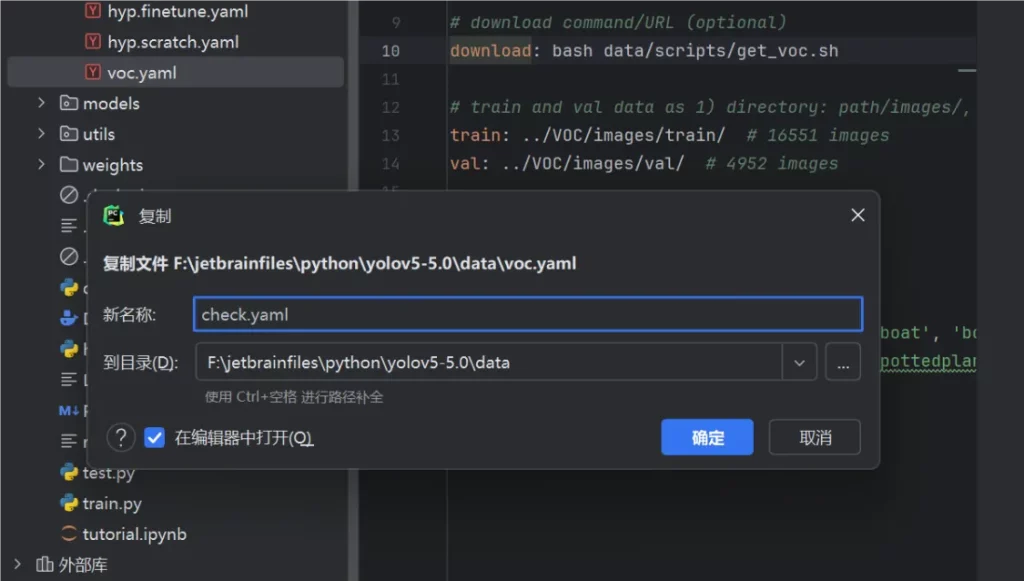
打开这个文件夹修改其中的参数,
- 首先将第十行代码注释掉,如果不注释这行代码训练的时候会报错;
10 #download: bash data/scripts/get_voc.sh
- 第13、14行中需要将训练和测试的数据集的绝对路径填上(最好要填绝对路径,有时候由目录结构的问题会莫名奇妙的报错);
13 train: ../VOC/images/train/ # 16551 images
14 val: ../VOC/images/val/ # 4952 images
- 第17行中修改参数为需要检测的类别数
17 nc: 20
- 最后第20行中参数填写需要识别的类别的名字(必须是英文,否则会乱码识别不出来)。
20 names: [ 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog','horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor' ]
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC/
# Train command: python train.py --data voc.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /VOC
# /yolov5
# download command/URL (optional)
#download: bash data/scripts/get_voc.sh
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: F:/jetbrainfiles/python/pythonProject1/VOC/images/train/ # 16551 images
val: F:/jetbrainfiles/python/pythonProject1/VOC/images/val/ # 4952 images
# number of classes
nc: 113
# class names
names: ["3+2-2", "3jia2", "aerbeisi", "anmuxi", "aoliao", "asamu","baicha","baishikele","baishikele-2","baokuangli","binghongcha","bingqilinniunai","bingtangxueli","buding","chacui","chapai","chapai2","damaicha","daofandian1","daofandian2","daofandian3","daofandian4","dongpeng","dongpeng-b","fenda","gudasao","guolicheng","guolicheng2", "haitai", "haochidian", "haoliyou", "heweidao", "heweidao2", "heweidao3", "hongniu", "hongniu2", "hongshaoniurou", "jianjiao", "jianlibao", "jindian", "kafei", "kaomo_gali", "kaomo_jiaoyan", "kaomo_shaokao", "kaomo_xiangcon", "kebike", "kele", "kele-b", "kele-b-2", "laotansuancai", "liaomian", "libaojian", "lingdukele", "lingdukele-b", "liziyuan", "lujiaoxiang", "lujikafei", "luxiangniurou", "maidong", "mangguoxiaolao", "meiniye", "mengniu", "mengniuzaocan", "moliqingcha", "nfc", "niudufen", "niunai", "nongfushanquan", "qingdaowangzi-1", "qingdaowangzi-2", "qinningshui", "quchenshixiangcao", "rancha-1", "rancha-2", "rousongbing", "rusuanjunqishui", "suanlafen", "suanlaniurou", "taipingshuda", "tangdaren", "tangdaren2", "tangdaren3","ufo", "ufo2", "wanglaoji", "wanglaoji-c", "wangzainiunai", "weic", "weitanai", "weitanai2", "weitanaiditang", "weitaningmeng", "weitaningmeng-bottle", "weiweidounai", "wuhounaicha","wulongcha","xianglaniurou","xianguolao","xianxiayuban", "xuebi", "xuebi-b", "xuebi2", "yezhi", "yibao", "yida", "yingyangkuaixian", "yitengyuan", "youlemei", "yousuanru", "youyanggudong", "yuanqishui", "zaocanmofang", "zihaiguo",]- 该项目使用的是yolov5s.pt这个预训练权重,所以要使用models目录下的yolov5s.yaml文件中的相应参数(因为不同的预训练权重对应着不同的网络层数,所以用错预训练权重会报错)。
同上修改data目录下的yaml文件一样,将model下的yolov5s.yaml文件复制一份,然后将其重命名
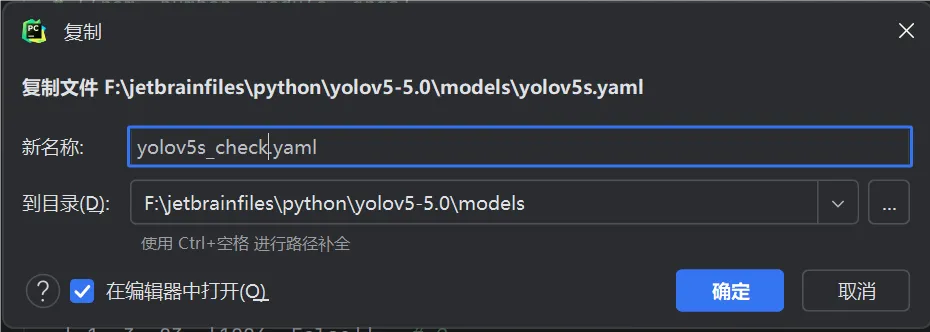
打开yolov5s_check.yaml更改第二行nc: 113 # number of classes将参数更改为标签类数量
开始训练:启用tensorbord查看参数
找到weights目录下的train.py文件
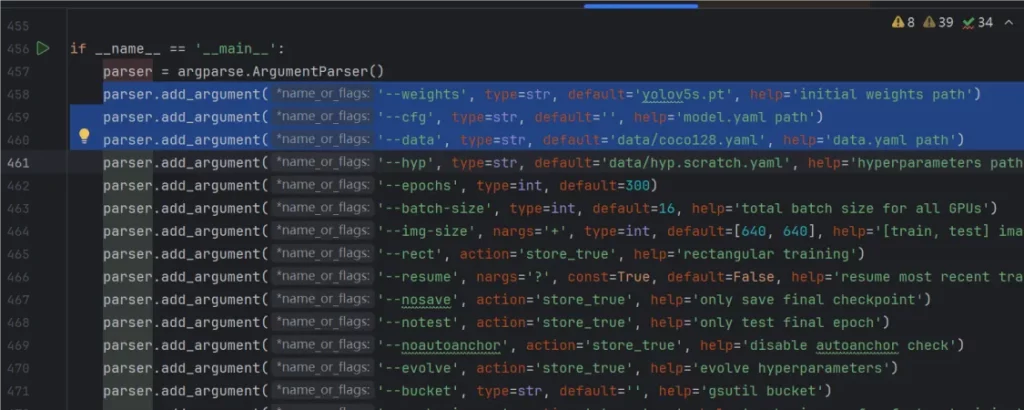
然后找到主函数的入口,应该是在456行左右
训练自己的模型需要修改如下几个参数就可以训练了。
首先将weights权重的路径填写到对应的参数里面(图中第458行)
然后将修改好的models模型的yolov5s.yaml文件路径填写到相应的参数里面(图中第459行)
最后将data数据的check.yaml文件路径填写到相对于的参数里面。这几个参数就是必须要修改的参数。(图中第460行)
parser.add_argument('--weights', type=str, default='weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='models/yolov5s_check.yaml')
parser.add_argument('--data', type=str, default='data/check.yaml', help='data.yaml path')这就是修改好的代码,填入的是相对路径
还有几个需要根据自己的需求来更改的参数:
- 模型的训练轮次,这里是训练的300轮。 (图中第462行)
parser.add_argument('--epochs', type=int, default=300)
- 输入图片的数量和工作的核心数(根据自己电脑性能来)第463、第480行(报错即调小)
parser.add_argument(‘–batch-size’, type=int, default=8, help=‘total batch size for all GPUs’)
parser.add_argument(‘–workers’, type=int, default=8, help=‘maximum number of dataloader workers’)
pycharm的用户可能会出现如下的报错。这是说明虚拟内存不够了。

在utils文件夹下找到datasets.py这个文件,将里面的第81行里面的参数num_worker改为0
至此,就可以运行train.py函数训练自己的模型
很好,上面的都是对的,但后面操作一眼难尽,教程有点早了。在后面我换了一个教程进行操作,很棒,直接解决问题,改用最新yolov5小版本。懒得记笔记了,记了也不会,就酱。
